
- 분류 전체보기 (153)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 8 그리드 시스템
- 패캠챌린지
- 뉴모피즘
- 패스트캠퍼스후기
- git
- SWIFT
- 뉴북
- 머티리얼 디자인
- 포인트
- 스큐어모피즘
- viewDidAppear
- 패스트캠퍼스
- viewDidLoad
- 직장인인강
- ios
- commit message
- Git Tutorial
- git workflow
- 픽셀
- 입력 개수 제한
- commit messages
- coordinator pattern
- Xcodebuild
- iOS앱개발올인원패키지Online.
- 아이폰
- 코드리팩토링
- 플랫디자인
- 디자인 트렌드
- 직장인자기계발
- commit
- Today
- Total
왕논의 연구실
파이썬 크롤링 예제 본문
앱을 만들려고 하다보면 인터넷에서 자료를 수집했으면 하는 부분이 있었다.
언젠가 해야지 해야지 하다가 직접 해보기로 했다.
우선적으로 실습해 볼 것
- 텍스트 크롤링
- 이미지 크롤링
2가지를 실습하는데 벌써 문제다.
텍스트 크롤링의 예제는 네이버 실시간 검색어인데, 실시간 검색어는 현재 서비스하고 있지 않다.
검색해서 찾아보니 검색어 순위를 알려주는 사이트를 3개 발견
1. zum
2. nate
3. 번개장터(인기 검색어)
3개 다 텍스트를 모아봤다. 그런데 각각 문제가 생겼다.
zum
- 검색어가 2개씩 읽혀진다. 개인적인 생각으로 주소링크 쪽 css의 클래스가 하나는 keyword로 끝나고, 하나는 keyword d_ready로 끝나는 걸로 봐서는, 하나는 현재의 검색어 랭킹이고 다른 하나는 바뀌는 검색어 랭킹이 아닐까 싶다. set이나 중복을 제거하는 함수를 사용해보면 어떨까 싶기는 하지만 뭔가 깔끔하게 떨어지는 느낌이 들지 않아서 패스했다.
nate
- 현재 보이는 보이는 쪽의 검색어만 보여준다. 네이트는 검색어를 5개씩보여준다. 1~5위를 보여준 후, 일정시간 후에 6~10위를 보여주는 것이 계속 반복된다. 그래서 크롤링하면 5개만 읽어 온다.
번개장터
- 번개장터는 검색창을 누르면 인기검색어를 볼 수 있게 해놓았다. 그래서 검색어 순위를 검색할 수 있게 css를 선택하였는데 전혀 읽어오지를 못했다. 혹시 안 읽어오나 해서 페이지 전체를 읽어왔더니, 인기검색어에 관련된 부분이 전혀 읽혀져오질 않는다. 웹페이지에서는 인기검색어 목록이 보이는데, 뭔지 잘 모르겠지만 채팅창을 눌러진 상태에서만 검색어를 보이게 해놓은 것 같다.
그래서 생각한게 요즘 사람들이 관심있고 순위가 보이는 네이버 금융 인기종목을 순위별로 검색해보기로 하였다. 순위별로 나열하고 파일을 생성해서 저장하는 것까지의 코드이다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://finance.naver.com/sise/lastsearch2.nhn') as response:
soup = BeautifulSoup(response, 'html.parser')
f = open("인기 종목.txt", 'w')
i = 1
for anchor in soup.select('a[href^="/item/main.nhn?code="]'):
data = str(i) + "위 : " + anchor.get_text() + "\n"
f.write(data)
print(data)
i = i + 1
f.close()

이미지 크롤링에서는 현재 라이브러리 에러가 있는듯하다.
그래서 pip install git+https://github.com/joeclinton1/google-images-download.git 로 라이브러리를 설치해준다.
설치할 때, pip 버전 경고가 뜨는 데 그것은 sudo pip install --upgrade pip 명령어로 업그레이드 시켜준다.
from google_images_download import google_images_download
response = google_images_download.googleimagesdownload()
arguments = {"keywords":"Polar bears,baloons,Beaches","limit":20,"print_urls":True}
paths = response.download(arguments)
print(paths)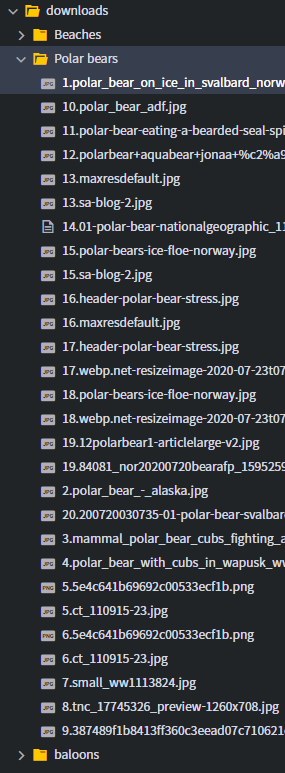
모두 해결되었다.